






众智FlagOS的统一通信库实现国家与国际标准“双立项”
 发布时间:2025-10-21
发布时间:2025-10-21
 信息来源:智源研究院
字体:
大
中
小
信息来源:智源研究院
字体:
大
中
小
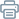 打印
发布时间:2025-10-21
信息来源:智源研究院
打印
发布时间:2025-10-21
信息来源:智源研究院
10月6日–17日,国际电信联盟(ITU-T)SG21日内瓦全会期间,基于众智FlagOS(面向多种AI芯片的统一开源系统软件栈)的统一通信库FlagCX技术,由智源研究院联合中国信息通信研究院牵头的ITU国际标准项目——《F.FUCL Requirements and Framework of Cross-Platform Unified Communication Libraries for Distributed Multimedia AI Systems》正式立项。
同期,10月5日,由智源研究院联合中国电子技术标准化研究院牵头制定的推荐性国家标准《人工智能 统一通信库接口规范》(立项计划号 20255428-T-469)顺利获批。
这标志着我国在多芯片通信与AI系统基础软件领域实现了国际标准与国家标准的同步突破,形成了“国内国际标准双驱动”的新格局。
该标准旨在屏蔽不同AI芯片间的架构差异与通信复杂性,构建统一、开放且可扩展的通信规范体系,促进跨芯片分布式任务的灵活迁移与高效协同,支持同构环境下的自适应跨场景优化及异构环境下的高效通信互联,从而打破算力孤岛,充分释放集群计算潜能,更好地为大规模分布式训练、推理以及端云一体化协同提供关键基础支撑。
01
双标准立项:协同推进的产业共识
面向多种AI芯片的统一通信库标准的成功立项,凝聚了科研、产业与标准化组织的合力,标志着我国在AI基础软件领域实现了从国内创新到国际协同的重要进展。
国家标准方面,《人工智能 统一通信库接口规范》由智源研究院与中国电子技术标准化研究院牵头,涵盖科研院所(北大、计算所等)、芯片企业(华为昇腾、寒武纪、昆仑芯等)、互联网企业(百度)、服务器企业(浪潮等)、运营商(移动、电信等)、网络系统提供商(基流科技)等几十家科研机构与企业单位共同参与。从启动到联合提案再到正式立项,历时一年多,期间多轮研讨,吸纳了广泛的行业意见,充分体现了产学研协同共建的行业共识。
国际标准方面,《F.FUCL Requirements and Framework of Cross-Platform Unified Communication Libraries for Distributed Multimedia AI Systems》由智源研究院联合中国信息通信研究院共同牵头,支持单位包括计算所、华为、百度、移动、电信、联通、国家电网、蚂蚁、浪潮等。在ITU-T SG21全会立项答辩,并获得来自美国、德国、英国、俄罗斯、日韩等多国专家的共识,最终通过立项,体现了我国在AI基础软件标准化领域的国际协同能力与技术影响力。
02
统一通信库标准:AI系统底座的关键枢纽
面向多种AI芯片的统一通信库标准通过为不同芯片上的通信库提供统一的规范接口与抽象,以屏蔽底层硬件差异与复杂性,支撑同构芯片上的跨场景自适应通信优化与异构芯片之间的高效跨芯通信,是AI计算生态多样化与高性能化发展的关键基础组件。如下图所示,其当前创新架构自上而下分为用户接口层、通信运行时层、可迁移抽象层三部分,并将在未来持续优化完善。

用户接口层
面向开发者与AI框架,提供统一高效的编程接口,包括插件接口、通信功能调用接口和编程语言接口。插件接口和通信功能调用接口用于向上对接不同AI框架(PyTorch、PaddlePaddle等)和构建于其上的训推框架(Megatron-LM、vLLM等)。通信编程语言接口负责为通信算子开发者提供轻量级接口,便于直接在C++/Python等编程语言中实现定制化通信算子以及通算融合算子开发,加速应用开发迭代。
通信运行时层
承担通信任务执行的核心逻辑,主要包括高层通信函数、中层通信操作、底层通信原语以及服务组件。高层函数实现编排与自适应优化,中层操作提供传统通信操作实现与融合算子的注册调用,底层原语提供高效的设备相关原语和第三方原语,保障极致的延迟与带宽表现。三层支持灵活调用,服务组件涵盖Proxy(网络异步收发机制)、Topology(拓扑管理与优化)等模块。
可迁移抽象层
屏蔽底层硬件与互联协议的差异性,为上层运行时提供一致的编程模型。其中,CCL Adaptor和Device Adaptor负责对不同类型的硬件进行统一抽象,包括GPGPU、ASIC、SuperPod等,分别封装了各类设备运行时(如CUDA、HIP等)及厂商原生通信库(如NCCL、RCCL等)。Net Adaptor和P2P Adaptor负责屏蔽底层互联协议的实现细节,对节点内互联协议(PCIe、NVLink等)和节点间网络互联协议(IB、RoCE等)进行统一封装。
通过创新分层架构设计,既能向上提供标准化的通信接口,便于各类AI应用的统一接入,又能向下通过可迁移抽象层开放适配机制,使芯片厂商能够轻松集成自研通信库或底层运行时,增强了系统的跨平台兼容性与可扩展性。
03
产业共识产业实践优先:FlagCX提供标准实现参考
开源统一通信库FlagCX(https://github.com/FlagOpen/FlagCX)作为上述两项标准的关键参考实现,已在多家主流芯片平台上完成适配与验证,并广泛应用于训练、推理等多种场景。通过“产业实践优先”的验证路径,有效保障了标准的可行性、时效性与前瞻性。
截至目前,FlagCX已——
●支持9种主流AI芯片,包括英伟达、寒武纪、昆仑芯、摩尔线程、海光、华为昇腾等。
●兼容IB、RoCE和TCP/IP三类网络协议和IBRC、IBUC、Socket、UCX四种网络协议软件栈。
●支持PyTorch与百度飞桨Paddle 3.0两大主流AI框架,其中Paddle实现原生集成。
FlagCX不仅在同构场景下与原生通信库性能持平,还通过自主创新的Device-buffer RDMA技术和Cluster-to-Cluster(C2C)异构统一集合通信算法,实现了跨芯片通信性能提升,成为全球范围内少数具备异构混合训练全栈开源能力的通信库之一。在近期升级中,FlagCX围绕跨芯通信效率实现两项关键突破:
1. C2C异构集合通信算法实现流水线并行化,带宽最高提升2.0×。
通过引入流水线并行来实现Pre、Inter、Post三个阶段任务的重叠,核心优化可以概括为两点:1)传输数据多Chunk切分,从而实现细粒度流水;2)多Stream并行,从而实现Pre/Post和Inter阶段的重叠。

我们通过实测ChipA 2机16卡对比了AllGather和AllReduce通信操作的已有的C2C算法和流水线并行优化后的C2C算法的性能数据(128K - 2G)。如下图所示:1)C2C AllGather算法使用流水线并行后相比之前算法带宽平均提升1.7x,最大提升2.0x;2)C2C AllReduce算法使用流水线并行后相比之前算法带宽在大通信量上(>=128M)平均提升1.3x,最大提升1.3x。


2. 零拷贝Device-buffer RDMA技术在小通信量场景下性能提升约3×,在大通信量场景与原生实现性能持平,达到业界领先水平。
如下图左所示,原生Device-buffer RDMA技术会在初始化阶段预先分配和注册一段可以允许从网卡直接拉取数据的Device-buffer(默认值64MB)。在实际通信过程中,FlagCX运行时会调用D2D拷贝实现应用程序的User-buffer和预注册Devic-buffer的数据传输。这会造成额外的数据拷贝开销,并严重影响小通信量场景P2P通信性能。为此,FlagCX将Device-buffer RDMA技术进行了zero-copy支持,如下图右所示,在初始化阶段通过直接注册User-buffer,避免实际通信过程中的D2D拷贝调用,从而允许网卡直接在User-buffer上进行数据读取和写入操作。

我们通过实测ChipA 2机2卡对比了零拷贝Device-buffer RDMA和原生实现的性能,如下图所示:1)在小通信量场景下(<=128KB),零拷贝Device-buffer RDMA相比原生实现可以达到大约3.0x的加速比;2)在[128KB, 128MB]的通信量区间内,零拷贝Device-buffer RDMA相比原生实现的加速效果随着通信量增大而不断降低,逐渐和原生实现性能持平;3)在大通信量场景下(>=128MB),零拷贝Device-buffer RDMA和原生实现性能持平。

同时,与业界其他通信库(如NCCL、VCCL、DLSlime等)对比表明FlagCX的零拷贝Device-buffer RDMA性能已达到业界领先水平(下图中DLSlime的128MB和1GB性能数据在我们的测试环境中未能成功运行,因此未包含其对比结果)。

众智FlagOS是面向多种AI芯片的统一、开源系统软件,而统一通信库 FlagCX 是其四大核心开源技术库之一。目前众智FlagOS 1.5版本在9月26日首届FlagOS开放计算开发者大会上由18个共创团队共同发布, FlagOS 1.5版本已经发展成为“4+3”的模式,即四大核心开源技术库+三大开源工具平台,通过开源技术库和开源工具平台的相互支撑,提供了更广泛的硬件支持、和更完善的组件协同。
除了统一通信库FlagCX之外,FlagOS还包括高效并行训推框架FlagScale、高性能算子库FlagGems,以及统一编译器FlagTree。其中,FlagScale支持多种芯片、多种后端,支持同构集群、异构集群的训练和推理上自动调优;FlagGems已建成全球最大、支持芯片种类最多的大模型通用算子库,支持了16家芯片厂商的25款AI芯片,覆盖GPGPU、DSA、RISC-V AI、ARM等多种芯片架构;FlagTree编译器累计支持12+国内外主流芯片厂商的20余种芯片型号。
04
标准引领未来:统一生态从中国方案到全球共享
FlagCX国际与国家标准的同步立项,是众智FlagOS从技术创新迈向标准引领的关键一步,也代表着一种开放协同的产业发展路径正在形成共识。我们深知,标准的生命力在于广泛的实践与应用。通过构建统一的跨芯片通信规范,我们期望的不仅是打破“算力孤岛”,更是与全球开发者和合作伙伴一道,共同促进AI基础设施的开放与融合,让每一份算力都能被高效、无缝地连接和释放。
目前,两项标准的编制组正依据国际与国内标准化流程,有序推进标准文件的起草工作。期待更多心怀远见的产业、科研机构与我们同行,参与到标准的研制与FlagOS生态的共建中来。让我们共同定义和构建一个更加开放、协同、可持续的全球AI未来。
相关人物






